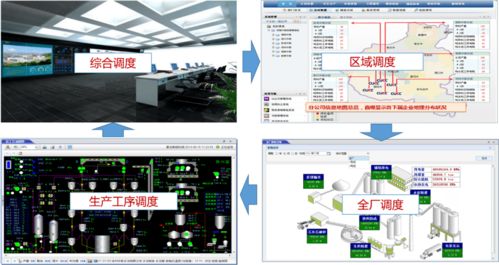
隨著工業(yè)4.0時代的到來,水泥行業(yè)正逐步向智能化轉(zhuǎn)型。水泥智能工廠的建設(shè)不僅能提升生產(chǎn)效率,還能降低能耗和運營成本,推動行業(yè)可持續(xù)發(fā)展。本文將圍繞水泥智能工廠的建設(shè)思路與人工智能應(yīng)用軟件開發(fā)進行探討。
一、水泥智能工廠的建設(shè)思路
- 總體規(guī)劃與分步實施:智能工廠建設(shè)應(yīng)基于企業(yè)現(xiàn)狀制定長遠(yuǎn)規(guī)劃,并分階段實施。需對現(xiàn)有生產(chǎn)線進行自動化改造,引入傳感器和物聯(lián)網(wǎng)技術(shù),實現(xiàn)設(shè)備互聯(lián)與數(shù)據(jù)采集。構(gòu)建數(shù)據(jù)中心,利用大數(shù)據(jù)分析優(yōu)化生產(chǎn)流程。集成人工智能技術(shù),實現(xiàn)智能決策與自主控制。
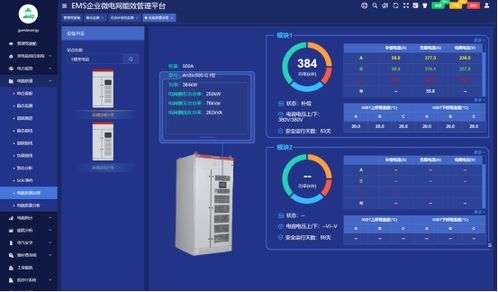
- 核心系統(tǒng)的構(gòu)建:智能工廠需具備智能生產(chǎn)管理系統(tǒng)、設(shè)備維護系統(tǒng)和能源管理系統(tǒng)。例如,通過人工智能算法預(yù)測設(shè)備故障,提前安排維護,減少停機時間;利用實時數(shù)據(jù)分析優(yōu)化能源使用,降低碳排放。
- 人工智能應(yīng)用軟件開發(fā):這是智能工廠的核心驅(qū)動力。軟件應(yīng)具備機器學(xué)習(xí)、深度學(xué)習(xí)等功能,能夠處理生產(chǎn)數(shù)據(jù)、優(yōu)化配方、控制質(zhì)量。例如,開發(fā)智能控制軟件,實現(xiàn)水泥生產(chǎn)的自動調(diào)節(jié);利用計算機視覺技術(shù),監(jiān)控生產(chǎn)線安全與質(zhì)量。
二、人工智能應(yīng)用軟件在水泥智能工廠中的價值
- 提升生產(chǎn)效率:通過人工智能算法優(yōu)化生產(chǎn)參數(shù),如溫度、壓力和時間,水泥產(chǎn)量和質(zhì)量得到顯著提升。例如,機器學(xué)習(xí)模型可以分析歷史數(shù)據(jù),推薦最佳生產(chǎn)方案,減少人為錯誤。
- 降低成本與能耗:人工智能軟件能夠?qū)崟r監(jiān)控能源消耗,預(yù)測需求波動,并自動調(diào)整設(shè)備運行模式。據(jù)統(tǒng)計,智能工廠可降低能源成本10-20%,同時減少原材料浪費。
- 增強安全與環(huán)保:應(yīng)用軟件可以集成安全監(jiān)控系統(tǒng),利用圖像識別檢測異常行為或設(shè)備故障,預(yù)防事故發(fā)生。通過優(yōu)化工藝,減少粉塵和廢氣排放,符合環(huán)保法規(guī)。
- 支持決策與創(chuàng)新:人工智能軟件提供數(shù)據(jù)分析和可視化工具,幫助管理者做出基于數(shù)據(jù)的決策。例如,預(yù)測市場需求變化,調(diào)整生產(chǎn)計劃;同時,軟件的可擴展性支持持續(xù)創(chuàng)新,如集成5G和邊緣計算技術(shù)。
水泥智能工廠的建設(shè)離不開人工智能應(yīng)用軟件的開發(fā)與應(yīng)用。通過系統(tǒng)化的思路和先進的技術(shù),企業(yè)可以實現(xiàn)高效、綠色和可持續(xù)的生產(chǎn)模式。未來,隨著人工智能技術(shù)的不斷成熟,水泥行業(yè)將迎來更多智能化突破。